
AI was everywhere at PHUSE US Connect 2026. You could feel it before the conference even started. A quick scan of the agenda tells the story: Lex Jansen ran the agenda through Claude and found that 33.8% of all sessions referenced AI, ML, or LLMs, making it the single most prevalent theme. Honestly, if you ask me, it felt closer to 99%! Every session with an AI component was packed.
Against that backdrop, AI Pulse was a timely, deliberate intervention which was held on the first day of the conference. Rather than adding another session about AI, we wanted to stop and ask: Where do we stand as an industry?
Not the vendor's pitch version, not the conference keynote version but the honest, anonymous, industry version. Over 75 people packed up the room, and what followed was one of the most candid conversations the PHUSE community has had on this topic.
Disclaimer: A note on the results – The survey gives the snapshot, not a complete picture. The responses reflect who was in the room on that day. On organization type, the audience skewed heavily toward sponsor companies (pharma and biotech) compared to CROs and technology vendors. On organization size, larger companies dominated, with enterprise organizations (>10,000 employees) being the most represented group. Additionally, participants could be from the same organization — which might have skewed results in one direction or the other. For privacy reasons, we did not parse out unique responses by the organization. Please keep both factors in mind as you read through the findings: the trends are meaningful and directionally useful, but the numbers should not be read as a precise, statistically representative view of the whole industry.
How the Session Worked
Using Mentimeter, a series of live polls was put together in front of the room and let the results appear in real time - anonymously, on screen for everyone. Out of the 75 attendees, around 48 people responded to each question on average. But this wasn’t just a passive survey readout. After each set of results appeared, we paused. The numbers sparked genuine conversation where attendees reacted, challenged each other, and shared context that the poll alone couldn’t capture. That live back-and-forth is what made the session feel different and engaging.

Q1: The One-Word Vibe Check
We opened with a simple warm-up: In one word, what comes to mind when you think about GenAI in Statistical Programming?

Efficiency dominated! The largest word by far followed closely by automation and revolution. These three alone tell a story of a community that sees GenAI primarily as a productivity multiplier. Look closer and you see a more nuanced picture: words like guardrails, regulatory, overhyped, and ‘fomo’ sit alongside superpower and new era. Enthusiasm and caution are travelling together and, that tension sets the tone for everything that followed.
Q2: Who Was in the Room?
Before diving into the substance, we asked attendees to identify their organization type so we could contextualize the responses. This helps interpret the results, since the mix of pharma, biotech, CROs, vendors and academic participants influences how representative the findings are.
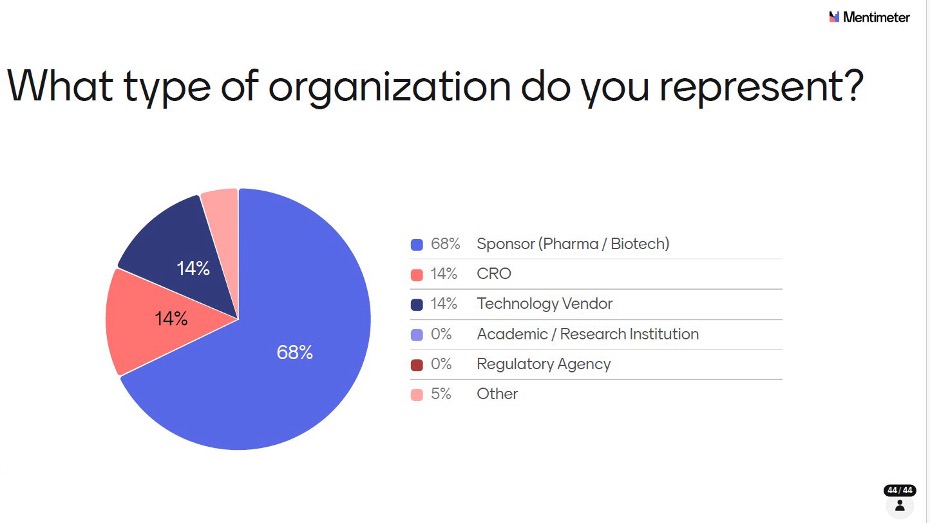
The audience was firmly sponsor-led: 68% from Pharma or Biotech, which is broadly representative of those who attend PHUSE US Connect. CROs and Technology Vendors each made up 14%, with 5% classified as ‘Other’. Note that multiple respondents may have come from the same organization, which could amplify certain perspectives particularly given the strong large pharma presence.
Q3: Organization Size
The size breakdown reinforced the large pharma skew.
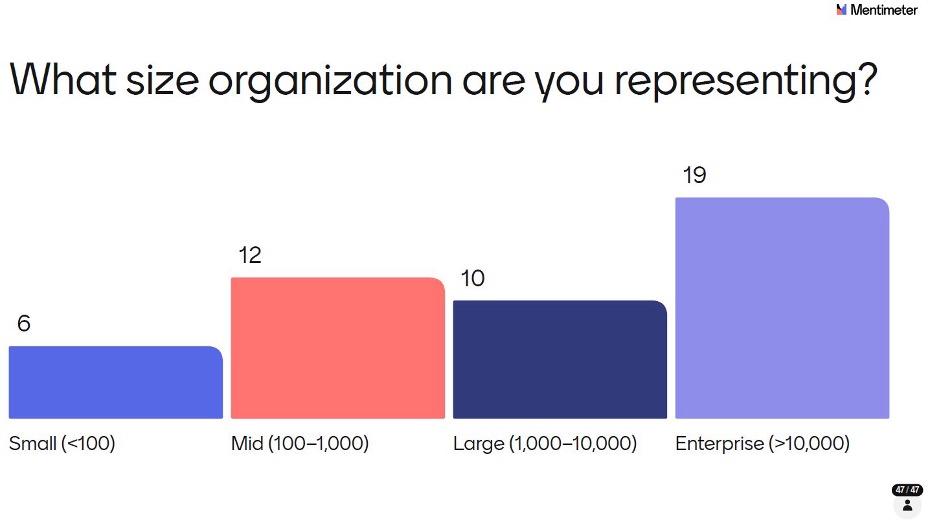
Enterprise organizations (>10,000 employees) had 19 respondents, Mid-sized organizations (100–1,000) had 12 respondents, Large organizations (1,000–10,000) had 10 respondents, and Small organizations (<100) had 6 respondents. Large pharma operates under some of the most complex governance, compliance, and data privacy environments in the industry, which helps explain the measured, cautious approach to AI adoption that surfaces throughout the survey. A room with more CROs, vendors, or smaller biotechs might have told a different story, and that’s one of the reasons we want to broaden the audience in future AI Pulse sessions. Despite the skew, we did get a genuinely useful directional read of how, where, and at what stages AI is being applied across statistical programming workflows.
Q4: Who Are These People?
The role breakdown confirmed that this was a deeply practitioner-focused audience.
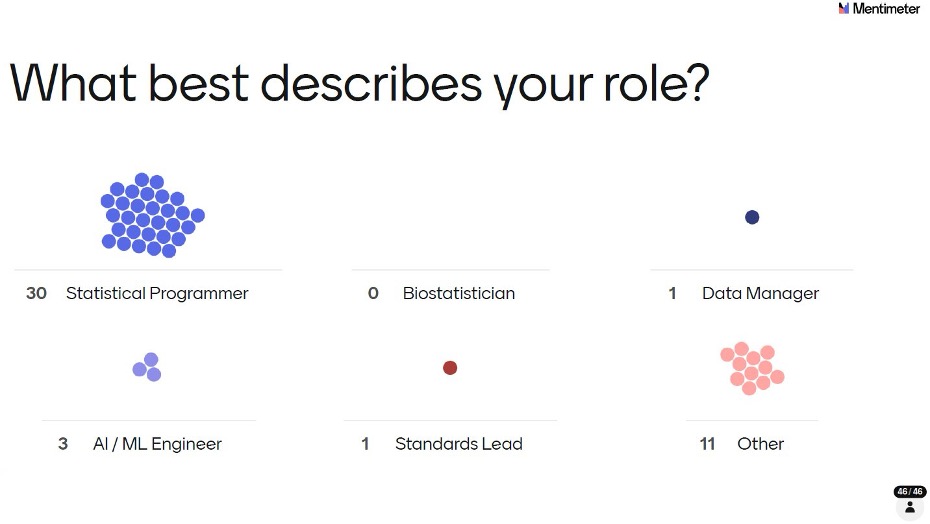
30 out of 46 respondents identified as Statistical Programmers, the single largest group by a wide margin. 11 selected Other (likely to include managers, directors, and other programming-adjacent roles), with 3 AI/ML Engineers, 1 Standards Lead, and 1 Data Manager rounding out the picture. Statistical Programmers have built their careers on embedding quality into every line of code within highly regulated environments, where errors carry significant consequences. Their cautious, validation-first approach to AI is therefore not surprising and is clearly reflected in the survey results presented below.
Q5: Where Is AI Being Applied?
With the room profiled, we moved into the substance of the survey. First up: where are people actually exploring or using AI in their work? A user could select multiple options.
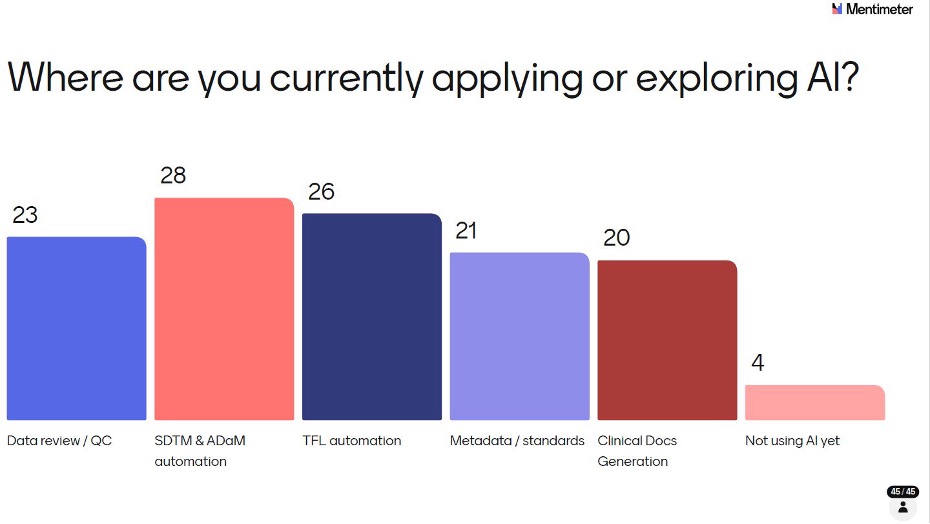
SDTM & ADaM automation received 28 votes, TFL automation received 26 votes, Data review / QC received 23 votes, Metadata / standards received 21 votes, and Clinical Docs Generation received 20 votes. Meanwhile, 4 respondents indicated that they are not using AI yet. Crucially, only 4 respondents said they weren’t using AI yet: meaning over 90% of the room had at least begun exploring GenAI in some corners of their work.
The breadth of application areas is notable: People aren’t waiting for a single killer use case. Experimentation is happening across the entire statistical programming workflow simultaneously. Bear in mind that org clustering may mean some of these application areas reflect the priorities of a handful of organizations rather than the industry at large.
Q6: Adoption Stage - Where Organizations Stand
Knowing where people are applying AI is one thing; knowing how far along they are is another.
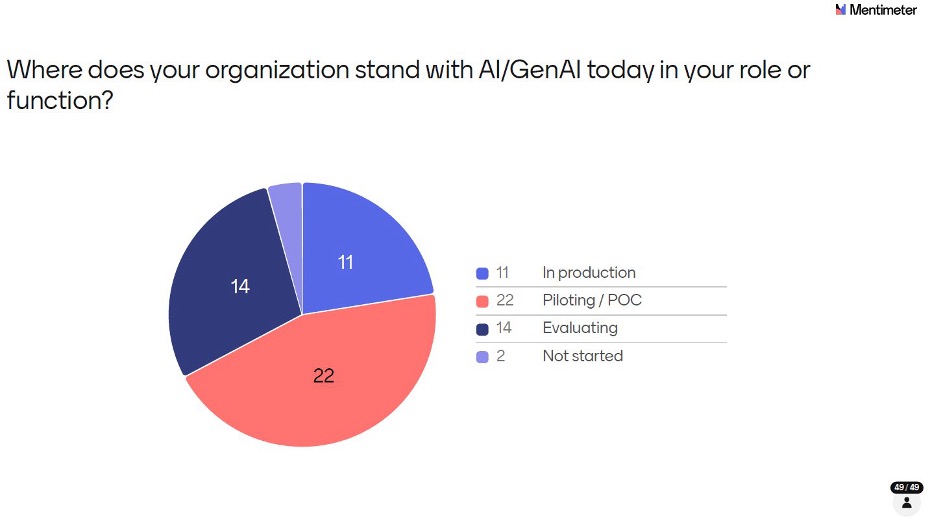
The largest group: 45% (22 out of 49 respondents) are in Piloting or POC mode, meaning they’re testing and learning but haven’t committed to production. 29% (14) are still Evaluating, and 22% (11) have moved AI into Production. Only 4% (2) said they haven’t started.
This distribution tells us the industry is past the ‘Should we look at this?’ phase and firmly in the ‘How do we make this work?’ phase. But with just 22% in production, scaling remains the challenge ahead.
Q7: How Integrated Is AI into Workflows?
We pushed further on integration - not just whether AI is in use, but how deeply embedded it is in daily work.
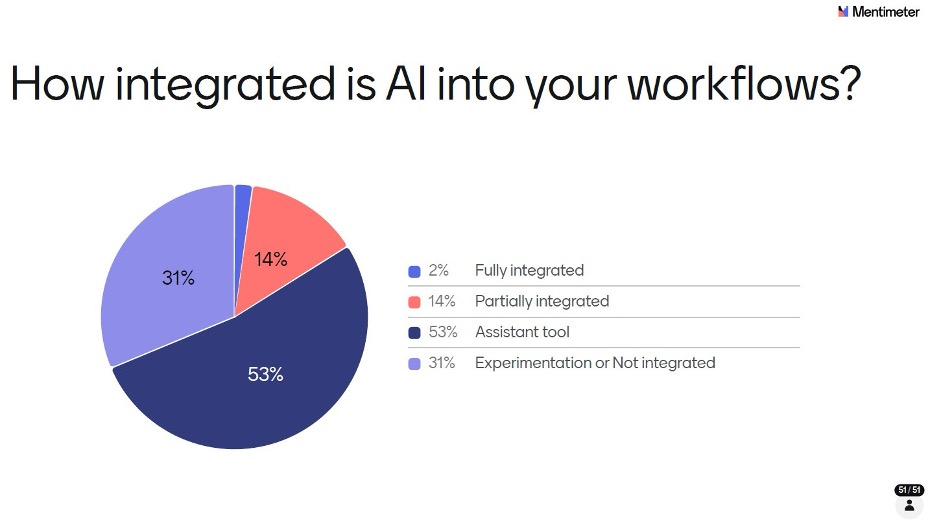
More than half (53%) described AI as an assistant tool — something they reach for to help with tasks on an ad hoc basis. 31% are still at the Experimentation or Not Integrated stage. Only 14% said AI is Partially Integrated into their workflows, and just 2% called it Fully Integrated. As with the adoption stage results, org clustering means these percentages may over-represent the practices of certain large organizations.
Stepping back, Q5 through Q7 together paints a consistent picture of where the industry sits on the adoption curve: broad exploration, active piloting, but limited production deployment and minimal deep integration. We are firmly in the early majority phase - past the innovators and early adopters, but with the bulk of the scaling journey still ahead. That context is worth carrying through as you read the remaining results.
Q8: Is AI Delivering Measurable ROI?
This was one of the most grounding questions of the session cutting through the enthusiasm to ask what’s actually being delivered.
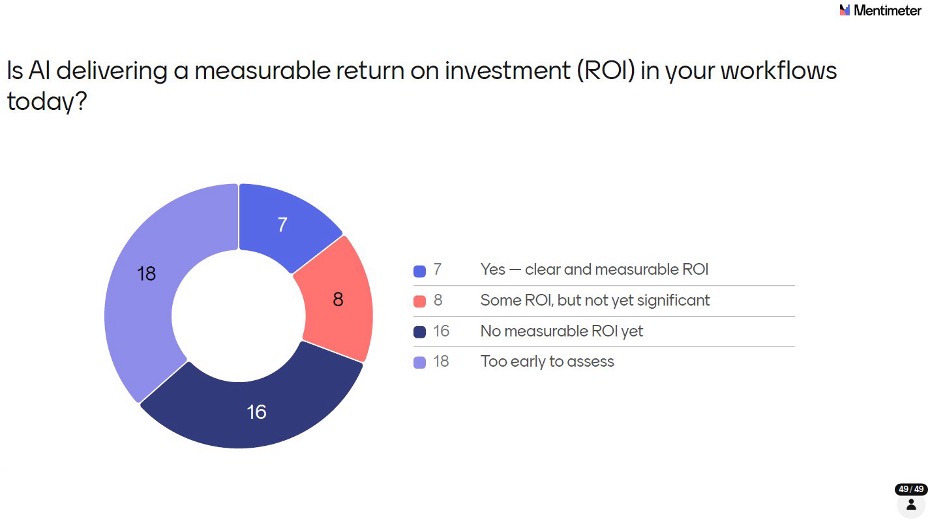
37% (18 out of 49 respondents) said it's Too Early to Assess - the largest single group. 33% (16) said there's No Measurable ROI Yet. Only 14% (7) could point to clear and measurable ROI, and 16% (8) reported some ROI but nothing yet significant. In total, fewer than a third of respondents could point to any meaningful return on their AI investment so far.
The numbers alone don't tell the full story. When the results appeared on screen, the room was quick to point out that ROI is genuinely difficult to quantify at this stage, not because AI isn't delivering value, but because the investment side of the equation itself is unclear. How much is an organization actually spending on AI implementation? Licensing, infrastructure, training, lost productivity during transition, validation effort - these costs are rarely tracked in one place, and industry-level benchmarks don't yet exist. Without a clear denominator, calculating a meaningful ROI is more or less impossible. The conversation in the room reflected a community that is pragmatic about this: the focus right now is on learning what works, not on proving a business case that the industry doesn't yet have the data to make.
It's also worth challenging the framing here. The 33% who said there's no measurable ROI yet may be setting an unnecessarily high bar. If AI is helping a programmer write a macro faster, resolve a bug in minutes instead of hours, or draft a first-pass specification that previously took a day - that is ROI. It may not show up in a formal business case, but it's real and it compounds. The industry may be overthinking what 'measurable' means, and in doing so, underselling the value already being realized.
Q9: What Efficiency Gains Are Being Realized?
We followed the ROI question with a more direct ask: what percentage efficiency improvement (in time or cost) have you actually seen from AI in your workflows?

The responses ranged widely from 0% to an eye-catching 95%. The most common answers clustered around 10% (7 responses) and 30% (6 responses), with 50% also well represented (5 responses). A handful reported 80% or higher. Excluding the one outlier response, the average efficiency improvement reported was approximately 32%.
The spread reflects the reality of early-stage adoption: in specific, well-scoped use cases, the gains can be dramatic. Across entire workflows, the picture is more modest. As the industry matures its use cases and builds validated pipelines, these numbers will be worth tracking carefully year on year.
In hindsight, this may not have been the most answerable question at this stage. When a task drops from 2 hours to 5 minutes, the percentage improvement is huge but not especially meaningful in aggregate. What matters is the direction: AI-driven efficiency gains are real and already underway.
Q10: What’s Holding AI Back from Scaling?
We asked respondents to identify the biggest barriers preventing AI from scaling in their workflows (pick up to 2).
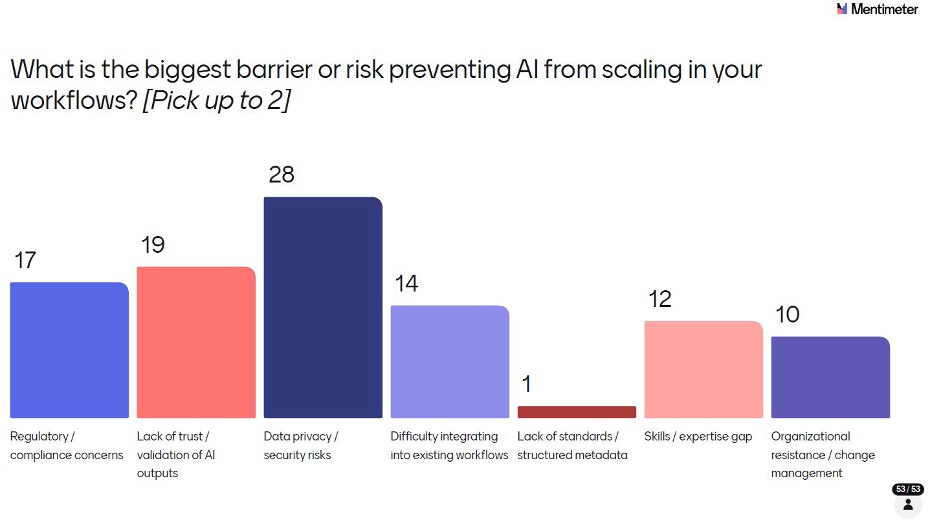
Data privacy and security risks topped the list by a clear margin with 28 selections - and the discussion that followed was one of the longest and most animated of the session. What emerged wasn't just concern about data privacy in the abstract, but a genuine confusion in the room about where LLMs actually stand today: how do they work, what data do they retain, and how can IT teams practically mitigate the risk of patient data exposure? Many attendees weren't clear about the answers, and that uncertainty is itself the problem. Others in the room stepped up to address and educate - explaining how enterprise-grade deployments, private instances, and data access controls can significantly reduce risk but the fact that this conversation needed to happen at all tells you something important about where the industry is.
Lack of trust and validation of AI outputs came second (19), and Regulatory/compliance concerns third (17). Difficulty integrating into existing workflows (14), Skills/expertise gap (12), and Organizational resistance/change management (10) all featured. Notably, Lack of standards/structured metadata received just 1 vote suggesting that while CDISC standards may need AI-readiness improvements, they're not seen as the primary blocker right now.
The data privacy finding connects directly to what you'll see later in the collaboration priorities question: the community is telling us clearly that education, shared resources, and governance frameworks around data privacy and security are not nice-to-haves - they are the foundation the rest of AI adoption in this industry must be built on. Stronger the implementation of governance more the trust.
Q11: Do People Trust AI in Regulated Clinical Workflows?
Trust is arguably the central question for GenAI in clinical statistical programming. We asked it directly.
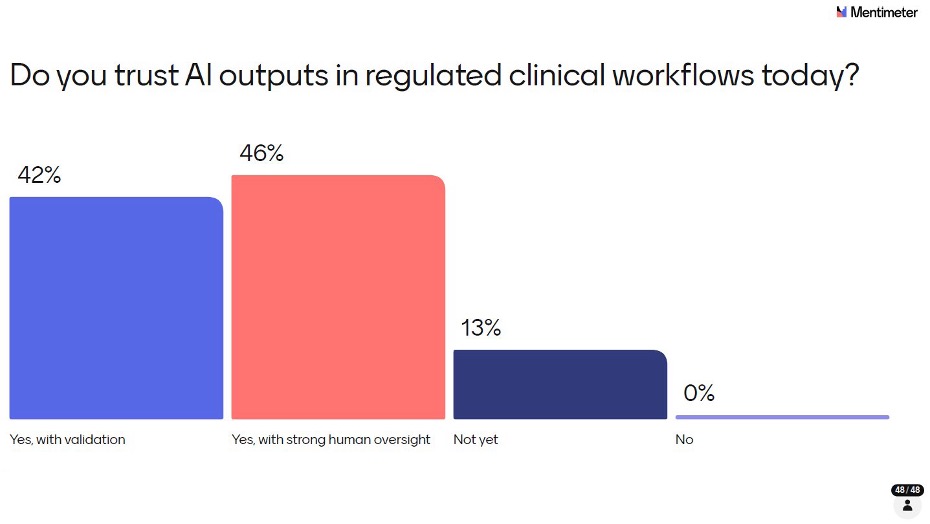
The result was striking that not a single respondent said a flat “No”. But the conditions attached to that trust matter enormously. 46% said yes but only with strong human oversight. 42% said yes but only with validation. 13% said they’re not there yet. Together, these responses show a community that is open to AI but demanding appropriate guardrails before trusting it in regulated contexts. Nobody is expecting AI to operate autonomously in clinical workflows anytime soon and that’s the right instinct.
It’s also worth distinguishing trust from confidence. Trust implies broad reliance, while confidence is specific to a validated result in a given context. In regulated environments, confidence is achievable through strong processes - unconditional trust likely isn’t and shouldn’t be. Viewed this way, the 88% who said “yes, under conditions” are expressing conditional confidence, not true trust and that’s the right answer.
Q12: Does Your Organization Have an AI Governance Policy?
Given that data privacy and regulatory concerns topped the barriers list, we wanted to understand how far governance frameworks have been developed.
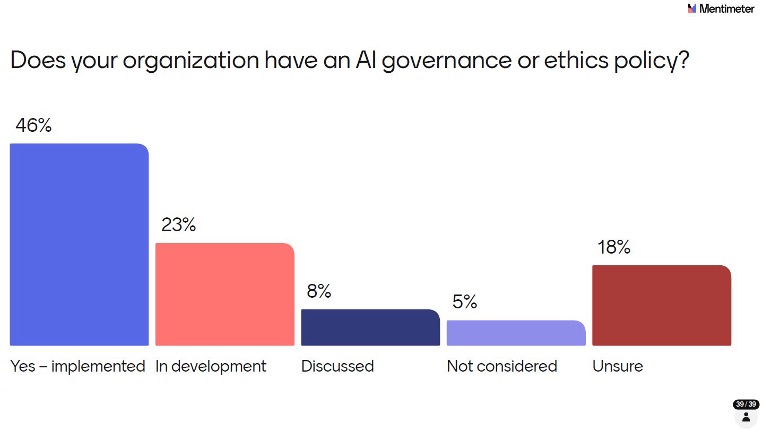
46% said yes - a policy is implemented. That’s an encouraging number. But 23% are still in development, 8% have only discussed it, 5% haven’t considered it, and 18% are simply unsure whether a policy exists at their organization. That last figure is perhaps the most telling: in a regulated industry, not knowing whether an AI governance policy exists is a governance gap in itself. As AI adoption accelerates, closing this awareness and implementation gap should be a priority for all organizations. It’s everybody’s opportunity as well as challenge.
Q13: Are CDISC Standards AI-Friendly?
We asked a question that sits at the heart of the industry’s infrastructure: are current CDISC standards actually set up to support AI adoption?
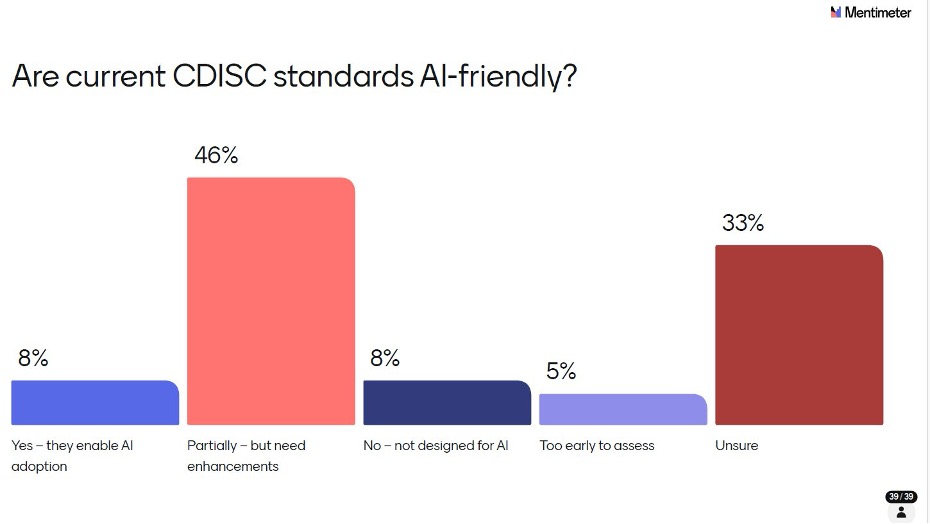
The plurality - 46% - said partially, but in need of enhancements. 33% were unsure, which itself signals that the community hasn’t yet deeply engaged with this question. Only 8% felt current.
standards fully enable AI adoption, and another 8% felt they were not designed for AI at all. The CDISC ecosystem has historically been a foundation for consistency and regulatory acceptance but building AI-readiness into that foundation will require deliberate effort. The fact that a third of respondents are unsure suggests this conversation needs to move from expert circles into the broader community.
We were fortunate to have Chris Decker, CEO of CDISC, in the audience, and we asked him to respond to the results directly. He offered valuable insight into the work CDISC has already done and continues to build upon including concept-based data models such as USDM, ARS, and Analysis Concepts and the ongoing CDISC 360i initiative, which is specifically focused on curating standards that are AI and automation enabled. That context resonated well with the attendees and visibly shifted the conversation: the question is no longer whether CDISC will engage with AI-readiness, but how quickly those efforts can be translated into tools and guidance that the broader community can act on.
The 33% who answered "unsure" is perhaps the most actionable finding here - it points to an awareness and communication gap that CDISC and the community can work together to close.
Q14: Where Should the Industry Collaborate?
The final poll asked respondents to think forward: where should the industry focus its collaborative energy to accelerate AI adoption in clinical workflows? (Pick up to 2)
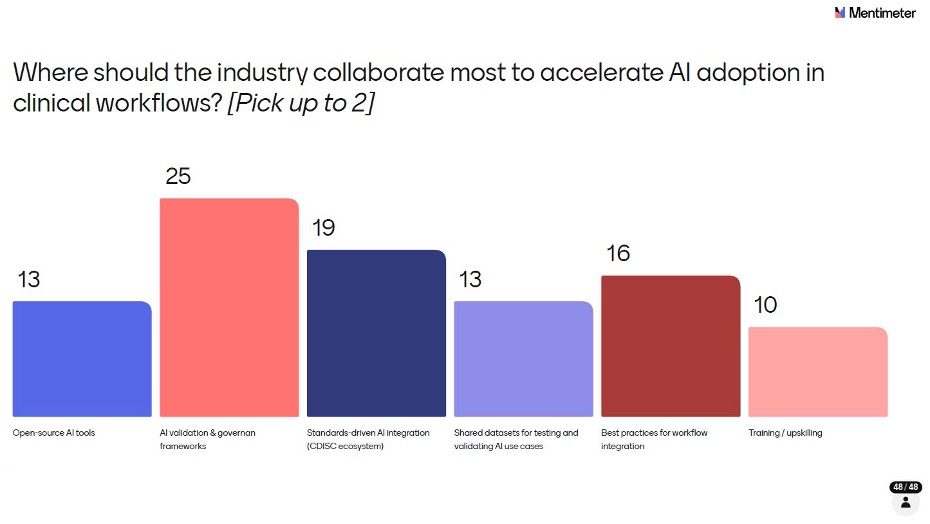
AI validation and governance frameworks led decisively, selected by 52% of respondents (25 out of 48). Standards-driven AI integration within the CDISC ecosystem was chosen by 40% (19), followed by Best practices for workflow integration at 33% (16), Open-source AI tools and Shared datasets for testing and validating AI use cases both at 27% (13 each), and Training/upskilling at 21% (10). Note that respondents could select up to 2 choices, so percentages reflect the proportion of attendees who prioritized each option rather than a share of a whole.
The message from the room was clear: the industry doesn't need more tools right now, it needs shared frameworks for trust, validation, and governance. That's the foundation everything else builds on.
The Breakout Session
After the polls closed, we structured a breakout session around the top three collaboration priorities identified in Q14:
1. AI validation and governance frameworks,
2. Standards-driven CDISC integration, and
3. Best practices for workflow integration.
Each of the 10 tables in the room was asked to discuss what is missing today, what the industry should do next, and who should lead or drive it - then share back one single clear action. Not a summary, not a theme but one concrete thing the industry should do next.
What the Tables Said: Actions from the Room
The feedback from each table was captured live and the 10 actions from the room were:
1. Alignment on AI governance.
2. Define a baseline for what AI validation is.
3. Establish a dedicated working group for AI validation, to evaluate bimonthly a white paper which provides the framework for what AI validation looks like.
4. Develop industry standard test datasets to validate AI tool performance.
5. Start implementing and identify appropriate company-level risk mitigation.
6. Best practices: sponsors should engage in knowledge sharing of best practices and potential pitfalls in use of AI, and hold their internal systems accountable for regulating AI access.
7. Follow industry big pharma, and have PHUSE and CDISC drive working groups and share learnings.
8. Train open source LLMs for pharma - noting this is not economically friendly on ROI for individual organizations.
9. PHUSE should build Model Context Protocol (MCP) servers and Skills and make them public.
10. Establish governance alignment across regulators and corporate compliance/governance across all departments.
What’s striking is how aligned the tables were despite working independently. Governance, validation frameworks, and shared industry infrastructure emerged as the dominant themes across the room - reinforcing what the poll data had already suggested. The community isn't short of ideas; it's short of coordinated action.
Across all 10 tables, the dominant themes were:
- Establish alignment on what AI governance and validation actually means in this context — not just as a concept, but as a defined, actionable standard.
- Create an industry working group focused on AI validation, producing white paper or framework on a regular cadence.
- Develop industry-standard test datasets that can be used to validate AI tool performance across organizations.
- Sponsors should actively share best practices and lessons learned, not keep AI learnings siloed internally.
- PHUSE should build and publish open infrastructure (including MCP servers and shared tools) that the whole community can build on.
- Establish governance alignment that spans regulators, corporate compliance, and all departments—not just the programming function.
One table made a point worth calling out directly: training open-source LLMs for pharma-specific use cases is not economically viable for most organizations in isolation. This reinforces the case for industry-level collaboration rather than every company solving the same problems independently.
What Comes Next
The AI Pulse session was designed to establish a 2026 baseline - a snapshot of where the statistical programming industry stands right now in the GenAI story. Based on the energy in that room at US Connect, it’s clear this conversation is only getting louder.
The plan is to bring AI Pulse back at future PHUSE Connect events, tracking how adoption, trust, barriers, and ROI shift as the industry matures. Year-on-year benchmarking will give the community something it doesn’t currently have: a real longitudinal picture of how GenAI is actually taking root in statistical programming - not just the hype, but the honest numbers.
Results will be shared through the PHUSE blog and community channels, and I look forward to channeling the energy from these sessions into working groups and collaborative projects through PHUSE and CDISC. Chris Price (PHUSE Working Group Director) and Chris Decker (CEO of CDISC), are both receiving copies of this report along with a follow-up to explore how we can take these actions forward together. Watch this space.
A huge thank you to everyone who attended and contributed to the survey - your candid responses are what made this session meaningful. A special thanks to my co-chairs Anupama Sheoran and Banoo Madhanagopal, and to the presenters from the ML/AI stream who worked with me to structure the survey questions and brought their expertise to the discussion on the day. Your collaboration and dedication made AI Pulse possible.
The AI Pulse session was moderated by Bhavin Busa at PHUSE US Connect 2026. All poll responses were collected anonymously via Mentimeter. If you are interested in getting involved in AI-focused working groups or contributing to the next AI Pulse session, reach out through the PHUSE community channels.
Download Full Session PaperFor more info please contact info@clymbclinical.com
Bhavin Busa
Principal and Co-Founder, Clymb Clinical
Latest Blogs
By Tawanna Childs
June 25, 2026
Clymbing Higher
From Midwest Roots to AI-Driven Biotech: Why I Moved to Boston.
I always envisioned trading in the Midwest for endless sunshine, crystal beaches, and tropical blooms. Somehow, my directionally illiterate self-ended up in the East Coast-where winters drag on, the days are shorter, traffic always wins and you quickly begin questioning your life choices.
By Tanaya Kondejkar
June 12, 2026
Beyond the Prompt: AI in Biostatistics, Statistical Programming and Medical Writing Workflow
We are living through a revolution where AI is reshaping how all industries operate. The clinical trial domain is one of the most complex industries but AI is very quickly transforming how the reporting side of it works. Clinical workflows follow strict regulatory standards. As someone building AI systems in this space, I’ve found that […]
By Shivani Gupta
April 16, 2026
Turbo TFLs: AI as our Sous-Chef
These days everyone wants to add a little AI tadka* into their daily work, and at my job, we’re no different. Just a few months ago, what I now lovingly call “the stone age”, we were still making Excel sheets, listing out program names, hunting for unique and duplicates, and building our TFL lists one […]
By Navin Dedhia
April 8, 2026
AI Isn’t Replacing Clinical Programmers – It’s Redefining the Role
There’s growing noise in clinical programming circles. Questions like “Will AI replace clinical programmers?” or “Will R automation eliminate manual TFL programming?” are becoming more common. But these questions miss the point.
By Clymb Clinical
April 8, 2026
Clymb Clinical at PHUSE US Connect 2026
PHUSE US Connect 2026 was one of the most active conference weeks in Clymb Clinical's history. Our team of seven traveled to Austin, Texas to present, exhibit, connect, and compete in the annual 5K Fun Run. Across five days, the Clymb team delivered five technical presentations, hosted two Clymbr Hub Lunch & Learn sessions, and came home with a Best Paper Award. Here is a look at everything that happened.