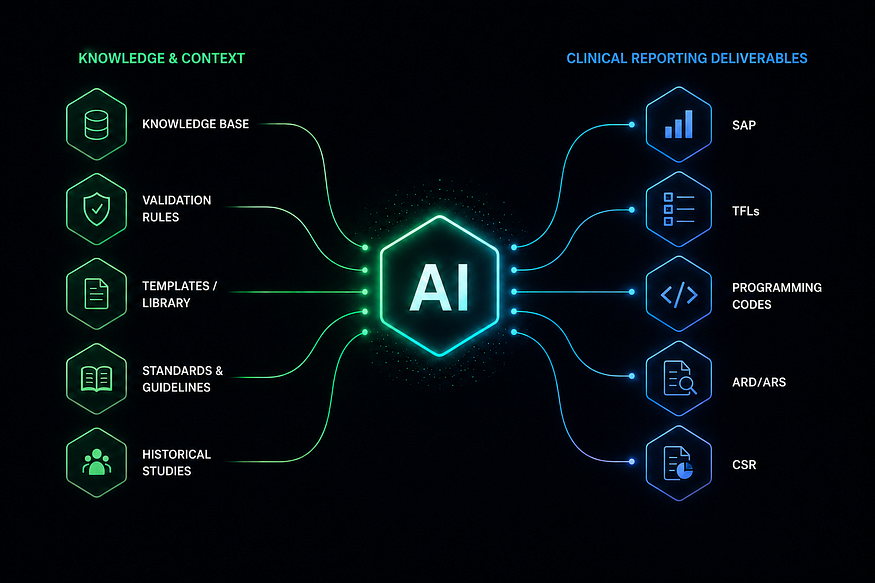
We are living through a revolution where AI is reshaping how all industries operate. The clinical trial domain is one of the most complex industries but AI is very quickly transforming how the reporting side of it works.
Clinical workflows follow strict regulatory standards. As someone building AI systems in this space, I’ve found that the hardest challenge is rarely getting a model to generate content. The real challenge is making sure that content is grounded, traceable and reliable enough to fit into a regulated workflow. Clinical reporting requires accuracy above everything else. There’s no room for error or “black-box” solutions where we can’t trace where the numbers or information comes from.
So the engineering question is not “can AI generate this document?” It is “can AI generate it and be trusted every time?” This is possible when AI is doing the right kind of work. Clinical reporting is pattern dense. Every rule a statistician follows when writing a SAP, every convention a programmer applies when coding a TFL, every structure a medical writer uses in a CSR are machine learnable patterns. When we encode this domain expertise into the model’s context, AI stops being a general purpose generator and becomes a reliable specialist. It applies those patterns consistently at scale, across every study. That’s exactly where we can get the maximum benefit.
What makes large language models (LLMs) particularly useful for clinical reporting is their ability to understand and generate structured content and patterns. SAPs, TFL specifications, programming standards and CSR narratives all follow recognizable patterns. The AI models are very good at learning these patterns and applying them consistently. The most valuable use of AI here is also information transformation. The protocol already contains the study intent. The SAP formalizes the analysis strategy. The TFLs define the required outputs. The CSR summarizes the results. Much of the reporting workflow consists of transforming information between these representations while preserving the traceability.
Models are also becoming increasingly effective at working with structured metadata. The AI models themselves are also evolving in reasoning, instruction following, code generation and long context understanding. Different models have different strengths. Some perform better on complex reasoning tasks, some on coding and some on processing large amounts of context. In practice, model selection is only one part of the solution. But at the same time, a model’s knowledge has limits. The model may understand CDISC concepts, common statistical methods and document structures because those patterns existed in its training data. What it does not know is the specific study being worked on, the sponsor’s standards, the approved templates or the latest decisions made by the team.
This is why retrieval systems and knowledge bases have become an important part of enterprise AI. The model, when provided with the relevant study documents, past user-created documents and standards at generation time, can learn from how the user writes it and generate content that aligns with existing conventions and study requirements. One of the biggest surprises for me was how often the quality of the context mattered more than the choice of model. We’ve seen cases where improving the references, templates and study context produced larger gains than switching to a newer model.
With this foundation, AI can thread through every stage of the reporting pipeline. At the SAP stage, AI grounded in guidelines and study protocol context can draft this document in hours rather than days. The statistician role shifts from author to reviewer. At the TFL stage, Code Generators that understand shell metadata, CDISC conventions and team specific SAS macros can produce study programs in minutes rather than hours. If we zoom out and think about this for a study of 100 TFLs we can recover weeks per study. At the CSR stage, AI framework which understands the protocol, SAP, the TFLs and the underlying context can create drafts which are guideline compliant, giving medical writers a populated first draft rather than a blank page. The numbers come from verified outputs rather than being generated by the model itself. At every stage AI stays grounded in the actual source material and the real compounding effect happens when all these stages connect.
This is the architecture we are building at Clymb Clinical, a flow that is not just faster at each step, but structurally more consistent and traceable end to end. The systems work on structured study metadata, document hierarchies, shell definitions, analysis specifications and reference standards. A protocol uploaded into SAP Builder creates the SAP which links to TFL Designer where the user creates shells and uses the AI code generator to generate outputs. TFL Viewer can be used for review and validation and CSR Builder helps create the report with in-text tables and sections ready.
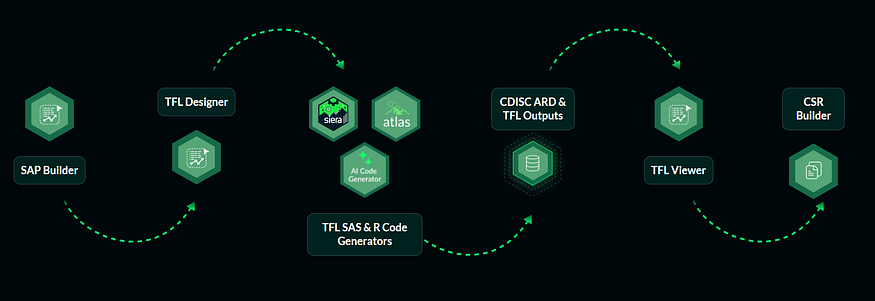
Fig. Overview of the Clymbr Hub
What excites me most is that we’re still early. The models continue to improve, but the bigger opportunity is figuring out how to combine them with domain expertise, structured data and clinical workflows in ways that create real value for study teams. The teams that figure out how to build on top of that wave rather than wait for it are the ones that will define how this industry operates for the next decade. And that’s exactly what the vision is at Clymb.
For more info please contact info@clymbclinical.com
Tanaya Kondejkar
Latest Blogs
By Tawanna Childs
June 25, 2026
Clymbing Higher
From Midwest Roots to AI-Driven Biotech: Why I Moved to Boston.
I always envisioned trading in the Midwest for endless sunshine, crystal beaches, and tropical blooms. Somehow, my directionally illiterate self-ended up in the East Coast-where winters drag on, the days are shorter, traffic always wins and you quickly begin questioning your life choices.
By Bhavin Busa
May 21, 2026
AI Pulse: Taking the Industry’s Temperature on GenAI in Statistical Programming
AI Pulse was one of the most talked-about sessions at PHUSE US Connect 2026. Moderated by Bhavin Busa, the session brought together 75+ statistical programming professionals for a candid, anonymous look at where the industry actually stands on GenAI adoption. The results may surprise you...
By Shivani Gupta
April 16, 2026
Turbo TFLs: AI as our Sous-Chef
These days everyone wants to add a little AI tadka* into their daily work, and at my job, we’re no different. Just a few months ago, what I now lovingly call “the stone age”, we were still making Excel sheets, listing out program names, hunting for unique and duplicates, and building our TFL lists one […]
By Navin Dedhia
April 8, 2026
AI Isn’t Replacing Clinical Programmers – It’s Redefining the Role
There’s growing noise in clinical programming circles. Questions like “Will AI replace clinical programmers?” or “Will R automation eliminate manual TFL programming?” are becoming more common. But these questions miss the point.
By Clymb Clinical
April 8, 2026
Clymb Clinical at PHUSE US Connect 2026
PHUSE US Connect 2026 was one of the most active conference weeks in Clymb Clinical's history. Our team of seven traveled to Austin, Texas to present, exhibit, connect, and compete in the annual 5K Fun Run. Across five days, the Clymb team delivered five technical presentations, hosted two Clymbr Hub Lunch & Learn sessions, and came home with a Best Paper Award. Here is a look at everything that happened.